

Beating the Odds and Succeeding as a Startup
Part II of my prep for CTO Craft Con


Beyond Planning
The temptation when preparing a talk on “Building a solid foundation for scalable structures, processes and values” is to follow the path of least resistance and haphazardly list some hand-picked scalability patterns and anti-patterns that I have observed during my long career. The risk is to end up with a compendium of anecdotical wisdom that reeks of bias and context-dependency. I’m terrified of seeing my content dismissed for being merely a rehash of the prevailing doctrine!
Even a seminal book like Robert L. Glass’ “Facts and Fallacies of Software Engineering” struggles to remain relevant after a couple of decades, with statements like “one of the two most common causes of runaway projects is poor estimation” looking quite dated in an age where Agile methodologies and movements like #NoEstimates support the use of empiricism in forecasting.
While I’m infinitely happy to have buried Gantt charts and Microsoft Project together in the cemetery of Waterfall Project Planning, I suspect that the pendulum has swung too far and planning in general gets a bad rasp that it doesn’t deserve.
Cynefin and Causality
After all, our Homo Sapiens ancestors had to resort to planning in order to stand a chance of successfully hunting mammoths and surviving. If our forefathers had been lucky enough to have access to the Cynefin framework, they would probably have classified mammoth hunting as a complicated domain with “known unknowns”, such as the weather, the terrain, the size and number of preys, how many hunters would be involved, etc. These factors change the probability of success of the hunt.
 on the ground using a stone. The rest of the group is watching with puzzled expressions, trying to make sense of the graph for their upcoming mammoth hunt.")
Our group of prehistoric hunters would have imagined the hunt and experimented with different scenarios, like evaluating the effect of increasing the number of hunters on the probability of dining roast mammoth meat vs coming back empty handed. They were using a causal model - without knowing it (no Directed Acyclic Graphs “DAGs” paintings were discovered in prehistoric caves).
We can organise our knowledge of the world into causes and effects because we
Can identify regularities in our environment
Can predict the effect(s) of deliberate actions on the environment, and select the most appropriate one to produce the desired outcome
We can infer reasons why some actions work and what to do when they
don’t, thus imagining worlds that do not exist.
What I reproduced is the description of the ladder of causation presented in “The Book of Why: The New Science of Cause and Effect” by Judea Pearl and Dana Mackenzie.
Give me Data!
Luckily, the global tech startup ecosystem as a whole is economically and statistically significant, with hundreds of thousands of businesses created in the last couple of decades. It represents a complicated domain with “known unknowns” where causal factors exist and can be harnessed by smart leadership teams. In that respect Steve Jobs may have been overly pessimistic when he stated
You can’t connect the dots looking forward; you can only connect them looking backwards.
-Steve Jobs
With nearly 150k VC-backed startups tracked by Pitchbook and $643 billion invested during the frothy days of 2021 accounted by Crunchbase, you’d imagine there’d be plenty of data available to dissect the success (and failure) factors for startups? However, most data providers like Dealroom are content to merely cover VC funding and startup hubs - presumably because VCs and governments have deeper pockets to pay for such research rather than scrappy startups.
Startup Lifecycle Stages
Among the few longitudinal studies of startups, “A Deep Dive Into The Anatomy Of Premature Scaling” stands out, painting a bleak picture of a startup world where 90% of ventures fail primarily due to self-destruction rather than competition. Ouch!
The results were published in 2011 by the Startup Genome and covered 3200 high-growth tech startups. They were accompanied by a 67-page analysis co-authored by researchers from UC Berkeley & Stanford studying both early and late stage startups, which are defined as
Early stage startups are designed to search for product/market fit under conditions of extreme uncertainty.
Late stage startups are designed to search for a repeatable and scalable business model and then scale into large companies designed to execute under conditions of high certainty.
-Steve Blank & Eric Ries
An influential contribution from the co-authors is an distinctive model of Startup Lifecycle Stages (a concept I mentioned in my previous post, A lifetime in software and nothing to say?). The report lists four discrete stages of development that apply to startups: 1. Discovery, 2. Validation, 3. Efficiency and 4. Scale. The naming is arbitrary but stages are clearly characterised by a different “dominant problem” that the startup must solve. Provocatively, the co-authors suggest that the solution often causes the startup’s next crisis - this is why working for a startup is never boring!

The Many Paths to Failure
Research from Steven H. Hanks from Utah State University in 1990, reveals that in an “Early Stage Startup”, a simple organisational structure is employed, with the founder(s) supervising the work of a few employees. Job assignments remain very general. There are few formal systems. Planning occurs on an ad hoc basis. We can all picture a few entrepreneurs working in a garage or university dorm room.
As startups trend toward a later stage of development, increased size (crossing the 40 engineers mark seems like a good rule of thumb) and complexity place new demands on the organisation, often rendering existing structures and systems ineffective - forcing a reconfiguration. Telltale signals that a reconfiguration is becoming urgent include:

Failure to reconfigure creates an overload on existing structure and systems, which in turn inhibits the organisation's ability to efficiently serve its customers. Timing this reconfiguration can be quite tricky - and the price to pay for mistakes can be as high as outright business failure.

Sadly I’m only too familiar with the top anti-pattern, i.e. building a product without problem / solution fit, since it was the root cause of two of my three startup failures as a co-founder (I was consistent at least, ahem!). This is a common trap for technical co-founders who are prone to become enamoured with their tech and spend their time over-engineering systems instead of tackling customer problems:
Premature scaling is trying to fix a problem you haven't encountered yet. It tends to happen mainly to tech founders where their desire to build cool technology gets in front of the real problem solving. You can detect it in long release cycles, constant failure to deliver and unused capabilities and/or product features.
- Alex Barrera, Serial Entrepreneur
For the engineering team, there’s the often obsessed about notion of having a robust platform that can handle millions of users before the startup even gets to 10’s of thousands on there.
-Michael A. Jackson, serial entrepreneur and investor
Accelerate
The research published in 2018 by Nicole Forsgren, Jez Humble, and Gene Kim in their book “Accelerate”, demonstrates that continuous delivery practices are a good predictor of improved business outcomes. It stands to reason that ceteris paribus a higher deployment rate supports a faster learning rate, and Startup Genome did find that
Founders that learn are more successful, raising 7x more money and having 3.5x better user growth.
-Startup Genome
“Accelerate” is one of those rare books that engineers are willing to enthusiastically endorse. Data for the book was collected from survey respondents who were asked to rate their organisation's relative performance on profitability, market share, and productivity using a validated scale of organisational performance - which is highly correlated with measures of ROI throughout economic cycles (outcomes instead of outputs).
Software delivery performance was found to significantly impact organisational performance:
High performers were twice as likely to exceed objectives in quantity of goods and services, operating efficiency, customer satisfaction, quality of products or services, and achieving organisation or mission goals.
-Accelerate
Authors used a robust set of statistical methods like hierarchical clustering, testing for bias, relationships and classification - uncovering 24 key capabilities that drive improvements in software delivery performance:

A finding of “Accelerate” is that as number of developers increases - as it normally does in any growing startup - the deployment frequency decreases for companies at the low end of the software delivering performance scale, while it increases dramatically for high performers. Thus the timely adoption of continuous delivery practices does reduce the pain of scaling and helps keep organisational performance high.
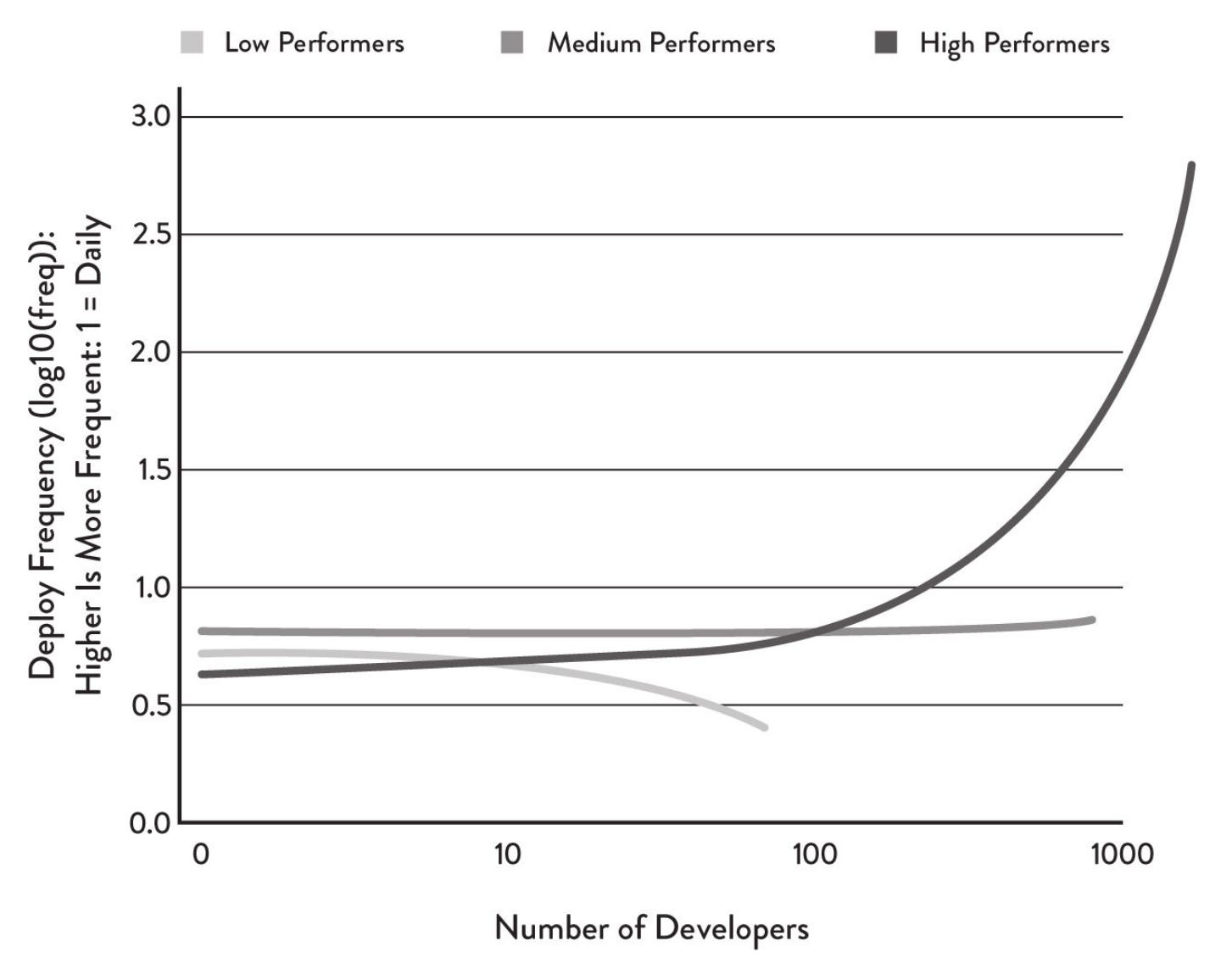
I discovered the “2023 State of DevOps Report” released in October 2023 as I was writing these lines. It is the single best source of information to understand the relationship between capabilities (which I call “factors” in this post) and outcomes. However, its scope is slightly different than mine, as 28.7% of the survey respondents are from companies with over 5000 employees, whereas I try to laser focus on early stage and scaling startups, typically smaller organisations.
Premature Hiring?
Staying on the headcount front, there are prominent examples of lean engineering teams supporting large customer or user bases in the B2B and B2C spaces:
37 Signals (Basecamp, etc.): < 80 engineers, ~100-150k customers, B2B
Linear: 15 engineers, > 1000 customers, B2B
Whatsapp (at acquisition time): 50 engineers, 1B users, B2C
Instagram (at acquisition time): 6 engineers, 30M users, B2C
Large engineering teams have been under the spotlight since Elon Musk’s controversial takeover of Twitter and the subsequent forced slim-down process he imposed. Here are some of the root causes for a suspiciously high headcount - that will in turn jeopardise the chances of success of a startup:
Large product surface, sometimes due to an excessive number of concurrent experiments stemming from a failure to ruthlessly prioritise investments - or the unwillingness to kill experiments that delivered limited market traction.
Overemphasis on building vs buying (“not invented here” syndrome), resulting in reinventing the wheel, often on non-core, non revenue-generating, software like billing, permissioning, developer tooling, etc.
Stakeholder pressure to hire faster, from investors or executives, most frequently to increase feature throughput but without a validated ROI hypothesis.
Let’s pause here to quote Stanford professor Robert I. Sutton co-author of the book “Scaling Up Excellence: Getting to More Without Settling for Less”. Personally, I do admit having a strong bias for hiring only when an extremely clear business need exists - and keeping a high selection bar.
In 2002, [Larry] Page once again got into trouble with his investors, his colleagues, and even prospective employees because he didn’t appear to be hiring fast enough. “But when you look back, it turns out that focusing on hiring the right people was critical to Google’s growth at that point”.
-Robert I. Sutton
Professor Sutton also introduces a few concepts that complement nicely the content of the Startup Genome report:
The hallmark of successful scaling is knowing when to hit the brakes in order to scale faster later. Founders need to slow down so that they can spread behaviours and beliefs first. There’s a hard tradeoff that must be considered: either running Business As Usual (BAU) initiatives - or paving the ground for future scale.
Scaling isn’t only about adding headcount, processes, etc. - it is equally important to subtract what doesn’t work anymore and slows the business down, like the wasteful handovers between teams.
Twitter Capabilities
Switching to the world of Big Tech, Chris Fry was an SVP of Engineering at Twitter and his scaling philosophy aligns well with my own experience at Twilio and Sylvera:
During the early stage of a startup, everyone does a little bit of everything, and almost all actions are reactive. This gets founders into the habit of staffing projects fast for short periods of time. When transitioning to a later stage startup, it is critical to move from individual identities to team identities by building strong and stable teams. The attributes of these teams are:
They have a clear mission
They have a leader accountable for success
They are cross-functional
They are self-healing and self-correcting organisms
They are small
There is a lot of evidence that as a team gets bigger than five, and the closer it gets to 10, you end up spending more time on coordination chores and less time doing the actual work.
Remove dependencies between teams so that they can ship faster. Teams that have a loosely coupled architecture are able to make significant changes to their systems without involving other teams. This enables teams to move faster. This is something Twilio does supremely well: each team owns a specific domain end-to-end, most often a product with its own API. For companies that embrace the Data Mesh approach, like Sylvera, each team is responsible for a data product.
Instagram Capabilities
Instagram’s co-founder Mike Krieger also has valuable recommendations for early stage startups, which should set them on a smooth path toward success:
Strive for simplicity, do not over-abstract
Optimise for minimal operational burden
Instrument and monitor extensively
Build a generalist engineering team, made of passionate and curious people
Ruthlessly prioritise delivering customer value
Build a diverse team early - the barrier only gets higher later on
When the startup is on the cusp entering the Scaling stage, he suggests a number of transformations:
Generalist engineering team → hiring team of specialised experts. They will help define the tech culture for the long haul, setting up the right environment, the right quality standards and the right ethos around engineering.
Flat organisation → promoting managers from within - but only if those engineers have an interest in growing that way.
Intercom Capabilities
Another source of wisdom is Intercom’s blog containing many strategies available when scaling a startup. The first entry in their list is unsurprising - it is our old foe, Premature Scaling / Optimisation:
Avoid premature optimisation: (the “root of all evil” according to Donald Knuth) Early stage startups have enough problems worth solving that are far more valuable and pressing than any of the mythical benefits of multi-cloud architectures, complex container orchestration systems like Kubernetes and high overhead micro-services. I can vouch for this: for years, the entire Twilio Authy 2FA service ran on a Ruby/MongoDB monolith, serving thousands of customers and millions of monthly active users. We only migrated Twilio Verify to Java, Dropwizard and DynamoDB after witnessing traffic spikes exceeding several hundred RPS.
Choose standard technology: Have a high bar for adopting shiny new tech. Write down exactly what it is about the current stack that makes solving the problem prohibitively expensive and difficult. Weigh up the operational costs and risks against the positive impact on your velocity. Over time, being constrained to solving problems with a small, specific set of standard tools, makes it easier to become experts in them.
Outsource undifferentiated heavy lifting: Engineering capacity, time and money are scarce, thus it is essential to be careful in deciding how to invest them. There’s a clear preference to spend on things that maximise value and minimise cost, both in the short and long term. Conversely, offload to 3rd parties as much responsibility that isn’t core to the customers’ experience, minimising the team’s operational burden and cognitive load.
Be reactive with costs: When building an entirely new service it can be very hard to estimate compute, storage and bandwidth costs. On the contrary, it is quite easy to sink a lot of time into cloud cost reduction projects, saving only a few dollars per month. But is any of this material to the future outcome of the business? At Twilio Account Security we started using AWS EC2 Reserved Instances when our usage patterns were well established. At Sylvera we optimised our Earth Observation data downloads once our spend was quite predictable and our main provider raised its prices.
Build in security: Intercom describes security as “job number zero” of Internet startups. This is especially true of fintech companies that have to comply with GDPR, PCI and must be SOC2 and/or ISO27001 certified. Baking in security in every product and feature from day one is way easier than adding it afterwards.
Ship, a lot: It is no coincidence that startups that were laser focused on shipping, like Intercom and Twilio, have become so successful. Unsurprisingly “Accelerate” is also Intercom’s bible.

For practitioners, the question is which of those capabilities deliver the best of ROI? This will depend on the level of investment (efforts, costs) required. As far as I know, there’s no comprehensive framework covering the ideal timing as well as investment for building startup capabilities.
Mighty Values!
Regardless, before scientifically improving performance, it is crucial to check and improve the company’s culture. Ron Westrum found that culture predicts the way information flows through an organisation, as well as performance outcomes.

“Accelerate” demonstrated that a Generative Westrum culture is a pre-requisite for high performance:
We hypothesised that culture would predict both software delivery performance and organisational performance. We also predicted that it would lead to higher levels of satisfaction. Both of these hypotheses proved to be true.
-Accelerate
Starting early when building culture helps hire and retain as well as scale up more effectively. Culture affects employer branding and is the company’s personality, mission, values - and even rituals. It influences how things are done and how decisions are made.
Here’s an easy way to picture how Values and Capabilities positively reinforce each other to mitigate Failure Factors, thus enabling Positive Outcomes for the business.

To use an example close to my heart, Twilio values have gone through several iterations since I joined the company in 2015, when it boasted only ~450 employees. I’m including below the values that were part of the original batch - or new ones that resonate with me. Twilio’s culture had a profound impact on my way of working - it features well thought-out Amazon-inspired values that bolster accelerated growth for any tech scale-up.
Wear the customers’ shoes
Draw the owl
Organise into small teams
Ruthlessly prioritise
Trust is the #1 thing we sell
Think long term
Be frugal
Seek progress over perfection
Be humble
Share problems, not solutions
Sylvera is at an inflection point between a early stage startup and a scale-up, with around 160 employees. Having less values makes them more memorable (I doubt that many Twilions except Jeff can remember on the spot the current set of 24 values).
Own it
Stay curious
Do what’s right
Collaborate with kindness
There’s no ideal number of values that every startup will need. The magic happens when values are put into practice. Every startup will find through trial and error a number that’s right for them. The objective is to focus on how these values will drive the right behaviours to create meaningful company value.
Values will evolve when the company grows and changes. For example, I don’t recall “organise into small teams” being a value at Twilio back in 2015. Values must be added - or removed - in response to change or a deeper understanding of the company’s situation.
Mechanisms to the Rescue
Even though the values are part of the fabric of the company, they cannot effectively enforce themselves - that’s the job of rituals - something that Amazon employees call mechanisms.
“Good intentions don’t work. Mechanisms do.”
-Amazon Saying
“The road to hell is paved with good intentions.”
-Anonymous
Amazon realised that if you don’t change the underlying condition that created a problem, you should expect the problem to recur. Twilio embraced the same philosophy. For instance, the mantra was that if your team experienced no incidents for a month you were either very lucky or very good - and that level of perfection can’t happen by accident. That’s why both Amazon and Twilio have put in place mechanisms to ensure that company values translate into action on the ground.

These mechanisms are the secret sauce of how top startups functions and are emblematic of their truest culture. What are the hallmarks of great mechanisms?
They have a template which lowers the barrier of adoption and enhances repeatability. I can’t stress enough how important this is!
They have a clear purpose and drive valuable - and often measurable - outcomes.
They allow leaders to better understand what’s happening in their business.
Their cadence is predictable and appropriate for their purpose.
Owners and participants are identified and invested in the mechanism.
They are often narrative-based as opposed to using slides since it helps leaders to summarise and assess complicated information.
They tend to be data driven and intentionally avoid weasel words.
Participants prepare (e.g. pre-read) ahead of the meeting, although they often start with a silent reading period anyway.
They’re a safe space which fosters active participation from all involved.
Accountability is promoted - and action items get done in a timely manner.
Knowledge sharing across all participants is reinforced.
Going deep into each individual mechanism would be beyond the scope of this post but great materials exist online, such as this blog post about Amazon PR/FAQs.
The Startup Capabilities Tree
We have seen several failure factors that range in seriousness from increasing the odds of negative outcomes (i.e. not achieving product-market-fit) to acting as grave scalability bottlenecks.
These factors apply to the early or the late stages of a startup’s lifecycle. Founders and their teams need to implement mitigation capabilities in a timely manner - not too early, nor too late. Premature scaling is a common cause of startup demise while delayed scaling will curb the growth potential of the business - or worse!
It is obvious that using your seed round proceeds to buy on-prem servers in order to avoid high cloud costs, as recommended by DHH, when your incipient business hardly has stable workloads, is the epitome of premature scaling. Cynefin chaotic and complex domains are firmly pre-scaling by nature.
For my conference presentation I have compiled in a Google sheet a total of 54 factors that may cause startups to fail or succeed, classified according to whether they represent premature or overdue scaling, their theme (e.g. Product, Tech, People, Structure, Process, etc.), the lifecycle stage that most closely matches the factor, and a rough guess of the factor’s impact on outcomes.
I will be connecting failure factors and their mitigating capabilities through graphical visualisations (likely DAGs) in my presentation. Stay tuned!

To go full circle and use an analogy, a startup developing a capability reminds me of a civilisation in a Real Time Strategy (RTS) game: you research a new technology in the tech tree to remain competitive and eventually graduate to the next age, which unlocks a new range of capabilities. Appropriately, tech trees are modelled as… DAGs, of course! Needless to say, you can’t skip a technological quantum step or a whole age - progress is sequential.
 with no other objects or text present.")
The similarity with RTS games doesn’t stop there: if you pick dictatorship as your political path, you can no longer hold democratic elections; likewise if you adopt holacracy as your company structure, you can’t build a management hierarchy anymore - and back-tracking can be enormously costly - just look at Zappos! Thus some capability choices are “one way doors” to quote Amazon, and must be made with great circumspection.
As opposed to civilisations in RTS games, real-life startups aren’t monolithic: it is quite likely that a large scale mature company like Google will incubate some disruptive product lines that are initially at an earlier stage of maturity than their core offering (think Photomath, Google’s most recent acquisition, vs Google Search), thus requiring a separate playbook optimised for discovery and validation.
(Input) Metrics
After a startup implements a (presumably valuable) capability, it is only natural to want to measure whether it is having a positive effect on outcomes.
If you can’t measure it, you can’t improve it.
–Lord Kelvin
Lagging metrics (e.g., profit, customer retention, etc.) represent the outcomes that a business wants to achieve. Amazon calls them “output metrics”. For a founder, the temptation is great to focus exclusively on output metrics with an aim to improve them.

However, at Amazon, leaders focus on a different type of metrics: “input metrics” (aka leading metrics) which are factors that can be controlled and changed. Input metrics like deployment frequency and lead time for change are to software delivery performance - and ultimately startup organisational success - what diet and exercising are to weight loss.
Amazon mechanisms are designed to bring constant leadership attention to these “input metrics” and foster the development of capabilities that will improve them.
Conclusion
This post outlined a framework for early stage startups and scale-ups to control their destiny, beat the odds and succeed, thanks to carefully selected values, capabilities and mechanisms that help mitigate common failure factors.

In the end, this framework is only an abstraction and has many limits. Nonetheless, I have seen it work well at successful scale-ups like Twilio and Checkout.com and we’re on a path to implement it at Sylvera.
Beyond that, I have a suspicion that lurking below the surface there are more basic positive and negative forces as well as thresholds influencing the success of a startup. Effective capabilities will amplify those positive forces or reduce negative forces. Crossing a threshold like Dunbar’s Number as the business grows will summon new forces, thus rendering some capabilities ineffective. The startup game is dynamic, ever changing.
As we reach the end of this post, it is worth pausing for a second and asking whether indefinite scaling is an unescapable law of nature?
Examine and interrogate your motivations, reject the money if you dare, and startup something useful. A dent in the universe is plenty.
-DHH
There is an alternative path: we can respectfully decline to play the startup game with its implied expectation of hockey stick growth and 100x returns fuelled and imposed by VC money. Instead we can make a smaller but still meaningful impact to our world, work toward controlled growth and profitability, steering clear of bloat and building a stayup instead of a startup.
The world is obsessed with Startups. We prefer to champion Stayups — companies who’ve proven their worth, figured out their businesses, and strive to stick around for the long term.
-37 Signals
Regardless of your choice, I hope that you have enjoyed reading this post.
Now on to distilling its content into slides that will fit into a 25-minute presentation!
Wish me luck!